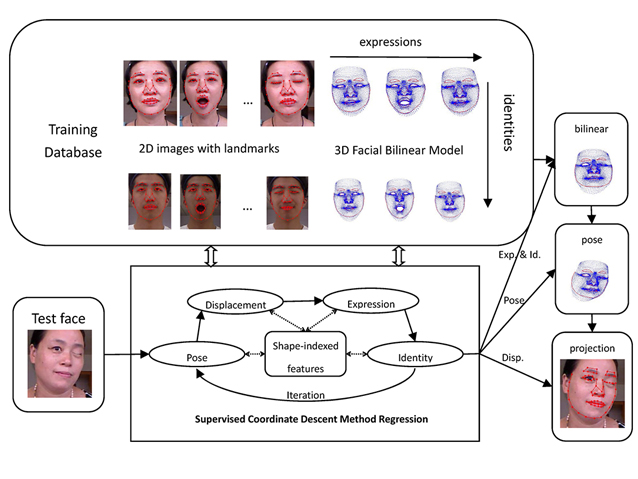
Face alignment and tracking play important roles in facial performance capture. Existing data-driven methods for monocular videos suffer from large variations of pose and expression. In this paper, we propose an efficient and robust method for this task by introducing a novel supervised coordinate descent method with 3D bilinear representation. Instead of learning the mapping […]